
De nieuwste computer- en laboratoriumtechnieken zijn indrukwekkend. De heilige graal is daarmee uit gigantische datasets iets overzichtelijks te maken, dat meer inzicht geeft in bijvoorbeeld de afstammingsgeschiedenis van de mens. Een internationale studiegroep beweert een ‘unificerende genealogie’ te hebben geconstrueerd, de stamboom van iedereen die ooit geleefd heeft.
Voor zestig euro doet een bedrijf een ‘eenvoudige’ DNA-test en belooft daarmee ‘de specifieke groepen waarvan u afstamt’ te onthullen. Best leuk, maar de vraag is wat die kennis ons leert. ‘Eenvoudig’ is geen adjectief dat goed past bij de techniek van gensequentie. Bovendien is de test zo goed als de database waartegen uw DNA vergeleken wordt. Want gaten in de data leiden tot gebrekkige resultaten en daar heeft niemand wat aan, behalve dat het fascinerend is dergelijke techniek min of meer aan den lijve te beleven.
De databases van de DNA-testbedrijven (er zijn er meerdere) verbeteren weliswaar met elke nieuwe klant (zo verdienen ze dubbel aan het groeiende bestand met genen), het adres van een ver familielid zal u niet vinden. Een complete stamboom met uw afkomst tot in vele generaties terug, levert zo’n test ook niet op. Het is geen genealogisch onderzoek, wat ook een leuke internethobby is. Handig om een oude voornaam in de familiegeschiedenis te zoeken voor de baby die op komst is. Misschien kom je nog een beroemde oudoom tegen. Het blijft fragmentarische kennis dat maar weinig inzicht in de afkomst en evolutie van de mensheid biedt.
In een zeer lezenswaardig artikel in Scientas wordt mooi uitgelegd hoe het sequencen, de sequentiebepaling, van een genoom in zijn werk gaat. Het genoom is het totaal van het genetisch materiaal van een organisme. ‘Lagere’ organismen hebben vaak heel complexe genomen, dat van de mens valt gek genoeg nog wel mee wat ingewikkeldheid betreft. Het genoom is het hele boek, de chromosomen de hoofdstukken en de genen zijn de woorden, die maar uit vier cijfers kunnen bestaan: de zogenaamde basen Adenine, Thymine, Guanine en Cytosine ofwel A,T,G en C, het genomische alfabet. Het boek van het genoom, geschreven met vier letters, is een miljoen pagina’s dik.
Het sequencen van genomen vierde in 2019 al zijn veertigste verjaardag, schreef Nature toen: “Een periode waarin we al getuige zijn geweest van meerdere technologische revoluties en een schaalvergroting van een paar kilobases naar het eerste menselijke genoom, en nu naar miljoenen menselijke en een ontelbaar aantal andere genomen”.
Ook zijn er genomen ontfutseld aan fossiele resten van oermensen en oude diersoorten. Vooral het genetische materiaal van uitgestorven mensachtigen, in het bijzonder een aantal Neanderthalers en een enkel Denisovan-mens, is spectaculair. In het DNA van de huidige mens zitten stukken genen van die oermensen. De verschillende technieken van gensequentie, de herhalingen en onderbrekingen in de sequenties en de enorme omvang van de bestanden maken de totale hoeveelheid data niet overzichtelijker. Een uitdaging op zich.
Rekenkracht
De datarevolutie heeft zich voltrokken door de rekenkracht van computers, de finesses van software en de organisatie van databases. Kunstmatige intelligentie en machine learning werken alleen met de enorme rekenkracht van (gekoppelde) computers. Moore’s Law uit 1965 voorspelde dat de rekenkracht van computers elke twee jaar zou verdubbelen. Daarmee zouden de kosten van omvangrijke bewerkingen (zoals gensequenties) omgekeerd evenredig afnemen. Dat kwam aardig uit. Maar dan moeten die computers ook nog wel iets zinnigs gevoerd krijgen en moeten de databestanden ook nog eens met elkaar geïntegreerd kunnen worden.
Doorbraak
Een doorbraak in het samenstellen van de genetische stamboom van de hele mensheid. Niets minder dan dat is het resultaat van het omvangrijke project van de universiteiten van Oxford, Harvard, MIT, Boston en Wenen. Biologie, antropologie, geschiedenis, genealogie, big data en kunstmatige intelligentie ontmoetten elkaar hierin. Het verslag verscheen in Science onder de titel ‘A unified genealogy of modern and ancient genomes’. (Hier de gehele tekst, legaal.)
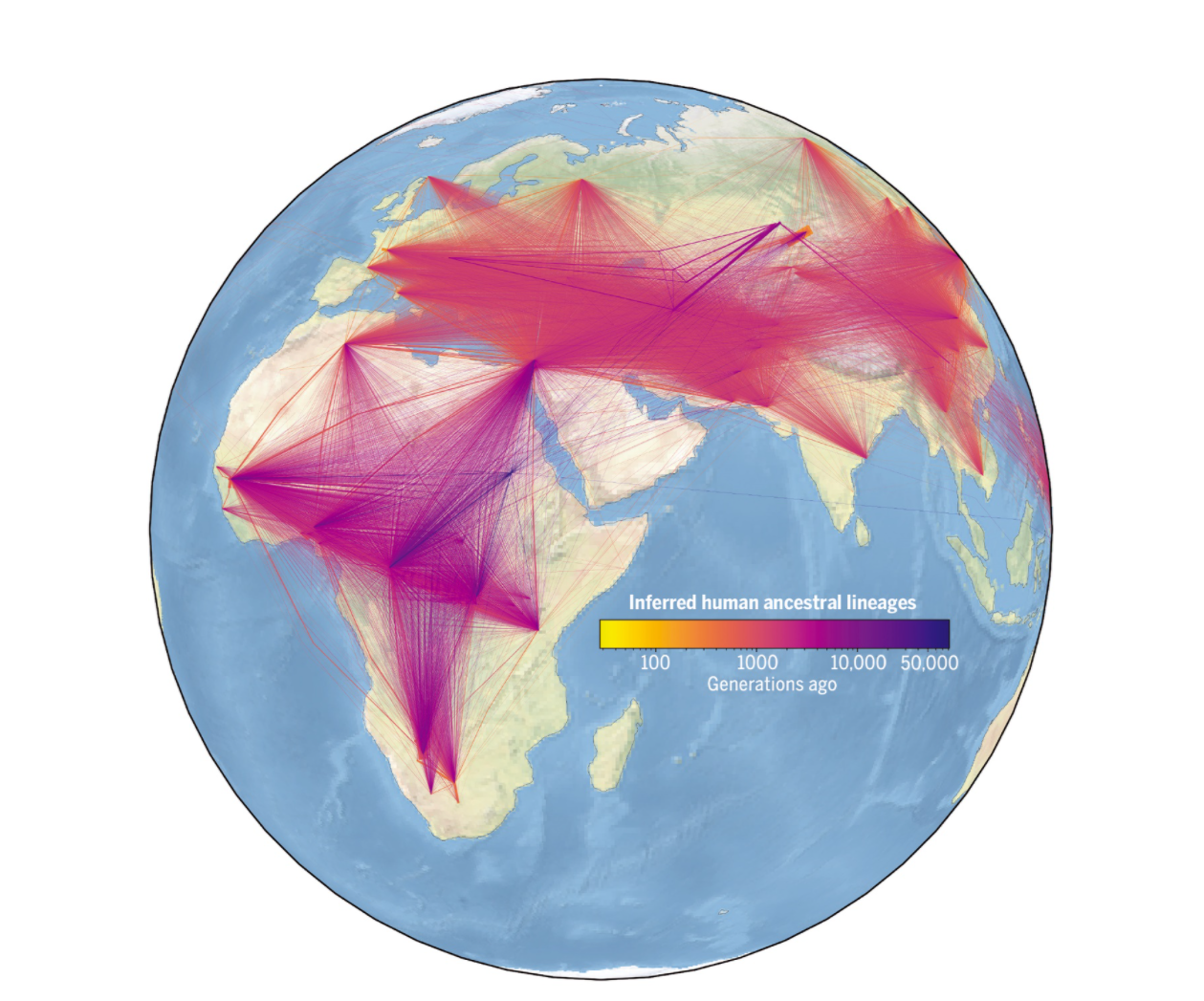
Unificerende theorieën zijn de heilige gralen voor de wetenschap en het lijkt erop dat deze studiegroep hier een heel mooi voorbeeld presenteert. Door duizenden genomen, moderne en oude, uit acht datasets te koppelen en er technieken op los te laten die feature extraction en tree sequences heten, construeren ze de afstammingsgeschiedenis van de gehele mensheid over het hele verspreidingsgebied van de mens op aarde over een periode vanaf het vroegste begin, meer dan 50.000 generaties geleden.
In totaal konden de onderzoekers uit de ruim 3.600 genomen, die tot wel 100.000 jaar teruggaan, 231 miljoen afzonderlijke voorouderlijke lijnen van afstamming opstellen. Die laten duidelijk de ‘out of Africa’-beweging van de vroegste mensen naar Eurazië zien. Ook toonden ze aan dat de eerste mensen 56.000 jaar geleden in de Amerika’s arriveerden, ver voor de grote migratie daarheen en veel eerder dan werd aangenomen.
Datzelfde geldt ook voor Nieuw-Guinea, waar de eerste lijnen al 100.000 jaar vroeger heen lopen dan de eerste sporen van menselijke bewoning die er gevonden zijn. Maar het kan zijn dat dit een vertekend beeld is. Dat alle bezitters van een heel oud genetisch kenmerk nu in de Amerika’s en Nieuw Guinea wonen is geen waterdicht bewijs dat hun voorouders daar ook al verbleven.
Het algoritme dat de stamboom samenstelt moet in de toekomst gevoed worden met veel meer dan de duizenden genomen die nu gebruikt zijn, wel miljoenen. Dat kan een veel preciezere invulling aan deze eerste schets geven, die voor een groot deel uit simulatie en invulling van datagaten bestaat. Maar het is al een overtuigende eerste stap naar een stamboom van iedereen die ooit leefde.
Dit artikel afdrukken
De databases van de DNA-testbedrijven (er zijn er meerdere) verbeteren weliswaar met elke nieuwe klant (zo verdienen ze dubbel aan het groeiende bestand met genen), het adres van een ver familielid zal u niet vinden. Een complete stamboom met uw afkomst tot in vele generaties terug, levert zo’n test ook niet op. Het is geen genealogisch onderzoek, wat ook een leuke internethobby is. Handig om een oude voornaam in de familiegeschiedenis te zoeken voor de baby die op komst is. Misschien kom je nog een beroemde oudoom tegen. Het blijft fragmentarische kennis dat maar weinig inzicht in de afkomst en evolutie van de mensheid biedt.
‘Lagere’ organismen hebben vaak heel complexe genomen, dat van de mens valt gek genoeg nog wel mee wat ingewikkeldheid betreftNeanderthaler
In een zeer lezenswaardig artikel in Scientas wordt mooi uitgelegd hoe het sequencen, de sequentiebepaling, van een genoom in zijn werk gaat. Het genoom is het totaal van het genetisch materiaal van een organisme. ‘Lagere’ organismen hebben vaak heel complexe genomen, dat van de mens valt gek genoeg nog wel mee wat ingewikkeldheid betreft. Het genoom is het hele boek, de chromosomen de hoofdstukken en de genen zijn de woorden, die maar uit vier cijfers kunnen bestaan: de zogenaamde basen Adenine, Thymine, Guanine en Cytosine ofwel A,T,G en C, het genomische alfabet. Het boek van het genoom, geschreven met vier letters, is een miljoen pagina’s dik.
Het sequencen van genomen vierde in 2019 al zijn veertigste verjaardag, schreef Nature toen: “Een periode waarin we al getuige zijn geweest van meerdere technologische revoluties en een schaalvergroting van een paar kilobases naar het eerste menselijke genoom, en nu naar miljoenen menselijke en een ontelbaar aantal andere genomen”.
Ook zijn er genomen ontfutseld aan fossiele resten van oermensen en oude diersoorten. Vooral het genetische materiaal van uitgestorven mensachtigen, in het bijzonder een aantal Neanderthalers en een enkel Denisovan-mens, is spectaculair. In het DNA van de huidige mens zitten stukken genen van die oermensen. De verschillende technieken van gensequentie, de herhalingen en onderbrekingen in de sequenties en de enorme omvang van de bestanden maken de totale hoeveelheid data niet overzichtelijker. Een uitdaging op zich.
Rekenkracht
De datarevolutie heeft zich voltrokken door de rekenkracht van computers, de finesses van software en de organisatie van databases. Kunstmatige intelligentie en machine learning werken alleen met de enorme rekenkracht van (gekoppelde) computers. Moore’s Law uit 1965 voorspelde dat de rekenkracht van computers elke twee jaar zou verdubbelen. Daarmee zouden de kosten van omvangrijke bewerkingen (zoals gensequenties) omgekeerd evenredig afnemen. Dat kwam aardig uit. Maar dan moeten die computers ook nog wel iets zinnigs gevoerd krijgen en moeten de databestanden ook nog eens met elkaar geïntegreerd kunnen worden.
Doorbraak
Een doorbraak in het samenstellen van de genetische stamboom van de hele mensheid. Niets minder dan dat is het resultaat van het omvangrijke project van de universiteiten van Oxford, Harvard, MIT, Boston en Wenen. Biologie, antropologie, geschiedenis, genealogie, big data en kunstmatige intelligentie ontmoetten elkaar hierin. Het verslag verscheen in Science onder de titel ‘A unified genealogy of modern and ancient genomes’. (Hier de gehele tekst, legaal.)
Unificerende theorieën zijn de heilige gralen voor de wetenschap en het lijkt erop dat deze studiegroep hier een heel mooi voorbeeld presenteert. Door duizenden genomen, moderne en oude, uit acht datasets te koppelen en er technieken op los te laten die feature extraction en tree sequences heten, construeren ze de afstammingsgeschiedenis van de gehele mensheid over het hele verspreidingsgebied van de mens op aarde over een periode vanaf het vroegste begin, meer dan 50.000 generaties geleden.
Het algoritme dat de stamboom samenstelt moet in de toekomst gevoed worden met veel meer dan de duizenden genomen die nu gebruikt zijn, wel miljoenenAlgoritme
In totaal konden de onderzoekers uit de ruim 3.600 genomen, die tot wel 100.000 jaar teruggaan, 231 miljoen afzonderlijke voorouderlijke lijnen van afstamming opstellen. Die laten duidelijk de ‘out of Africa’-beweging van de vroegste mensen naar Eurazië zien. Ook toonden ze aan dat de eerste mensen 56.000 jaar geleden in de Amerika’s arriveerden, ver voor de grote migratie daarheen en veel eerder dan werd aangenomen.
Datzelfde geldt ook voor Nieuw-Guinea, waar de eerste lijnen al 100.000 jaar vroeger heen lopen dan de eerste sporen van menselijke bewoning die er gevonden zijn. Maar het kan zijn dat dit een vertekend beeld is. Dat alle bezitters van een heel oud genetisch kenmerk nu in de Amerika’s en Nieuw Guinea wonen is geen waterdicht bewijs dat hun voorouders daar ook al verbleven.
Het algoritme dat de stamboom samenstelt moet in de toekomst gevoed worden met veel meer dan de duizenden genomen die nu gebruikt zijn, wel miljoenen. Dat kan een veel preciezere invulling aan deze eerste schets geven, die voor een groot deel uit simulatie en invulling van datagaten bestaat. Maar het is al een overtuigende eerste stap naar een stamboom van iedereen die ooit leefde.
Visualisatie van afgeleide menselijke voorouderlijke lijnen in tijd en ruimte.
Elke lijn vertegenwoordigt een voorouder-nazaat-relatie in onze afgeleide genealogie van moderne en oude genomen. De breedte van een lijn komt overeen met het aantal keren dat de relatie is waargenomen, en lijnen zijn gekleurd op basis van de geschatte leeftijd van de voorouder.
Uit: SCIENCE VOL. 375, NO. 6583 A UNIFIED GENEALOGY OF MODERN AND ANCIENT GENOMES
Elke lijn vertegenwoordigt een voorouder-nazaat-relatie in onze afgeleide genealogie van moderne en oude genomen. De breedte van een lijn komt overeen met het aantal keren dat de relatie is waargenomen, en lijnen zijn gekleurd op basis van de geschatte leeftijd van de voorouder.
Uit: SCIENCE VOL. 375, NO. 6583 A UNIFIED GENEALOGY OF MODERN AND ANCIENT GENOMES
Nog 3
Je hebt 0 van de 3 kado-artikelen gelezen.
Op 5 mei krijg je nieuwe kado-artikelen.
Op 5 mei krijg je nieuwe kado-artikelen.
Als betalend lid lees je zoveel artikelen als je wilt, én je steunt Foodlog
Lees ook











